Case Study 2: The RSF project № 18-71-10001
Personal Knowledge Base Designer was used in the project of the Russian Scientific Foundation № 18-71-10001 "Methodology and tool platform for the development of software for data extraction from arbitrary spreadsheets".
In particular, it is used in the case of spreadsheets analysis in the field of industrial safety inspection (ISI). The ISI is a procedure for assessing the technical condition of industrial facilities, in order to define the residual life of the operated equipment and the degradation processes. Rule-based expert system can be used for solving some ISI tasks ("development of an ISI program"; "analysis (including interpretation) of the diagnostics results"; "making decisions for the repair" and "forming a conclusion (report) for ISI").
It was decided to develop a prototype of the knowledge base based on the analysis of spreadsheets from ISI reports. These spreadsheets, in most cases, contain already structured information and some relationships between concepts. 216 spreadsheets were processed, 149 concepts and 27 relationships were extracted. The knowledge base containing 21 templates for facts and 9 templates for rules is designed. In the project the PKBD functionality was extended to support the analysis of TabbyXL canonical tables obtained as a result of transformation of arbitrary tables from ISI reports.
The knowledge base engineering process based on the analysis of canonical tables can be presented in the form of a diagram (Fig.1).
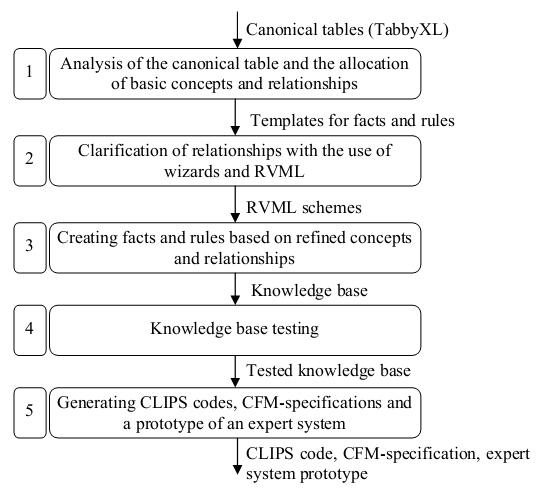
Fig.1 The diagram of knowledge base engineering based on canonical tables analysis using PKBD
Next, let’s consider an example of the development of a fragment of the knowledge base according to this diagram. Only one canonical table will be processed.
Step 1. The following concepts were defined as a result of the analysis of the canonical table (Fig.2, the table is translated into English): structural element and material. Each concept is characterized by a set of properties. Relationships are also defined between concepts. Selected entities are converted to fact templates with slots, relationships are converted to rule templates. The original spreadsheet from an ISI report is shown in Fig.3 (the table is translated into English).
At this stage 173 unique (with a unique layout and content) and 5817 cells with entities were allocated from 216 tables. Only 161 tables were successfully converted and 429 concepts were extracted,including 59 entities, 338 properties, and 32 relationships. After aggregation, as well as qualitative evaluation by experts of the obtained models, 242 concepts (25 entities, 196 properties and 21 relations) were used for further processing (about 56% of the original concepts).

Fig.2 The fragment of the analyzed canonical table

Fig.3 The source table from an ISI report
Step 2. The obtained templates were edited using PKBD wizards. In this case, each template corresponds to the RVML scheme (Fig.4). When analysing several files with canonical tables at once, concepts and relationships are aggregated, for example, Fig.5.

Fig.4 RVML representation of a rule template

Fig.5 RVML representation of an aggregated rule template
Thus, fragments of the knowledge base are obtained, which are subject to verification and validation. The 3-5 steps are similar to the Case Study 1: The IrkutskNIIHimmash project № 052013.
To evaluate the proposed approach, the recall and precision of the transformation of tables from ISI reports were calculated. TabbyXL and PKBD were used to implement the following transformations: (a) arbitrary tables-to-canonical tables and (b) canonical tables-to-conceptual models. Thus calculations were made for each means:
| Transformation / Assesment | Recall | Precision | F |
| arbitrary tables-to-canonical tables (TabbyXL) | 0.87 | 0.99 | 0.93 |
| canonical tables-to-conceptual models (PKBD) | 0.96 | 0.97 | 0.97 |
| average | 0.92 | 0.98 | 0.95 |
In terms of comparing the content of the models, the experts found that 17% (69 out of 400) of the concepts obtained earlier models have identical concepts from the resulting tables, including entities, properties, and relationships. In this case, the coincidence (correspondence) reaches 24% (106 out of 400), in the case of the possibility of supplementing the concepts from the models with the relevant properties of the corresponding concepts from the tables.
Quantitative characteristics of the compared sets:
| Dataset / Сriterion | amount of concepts | amount of entities | amount of properties | amount of relationships |
| Source tables | 429 | 59 | 338 | 32 |
| Selected tables (56% of the source tables) | 242 | 25 | 196 | 21 |
| Models for comparison (21 PCs) | 400 | 98 | 249 | 53 |
| Matching (17% of model elements) | 69 | 14 | 51 | 4 |
| Matching and supplemented (24% of model elements) | 106 | 14 | 88 | 4 |
Thus, the use of tables from ISI reports allowed us to automatically create 24% of the concepts of the ISI subject model, providing a basis for the creation of the knowledge base.
At the same time, 60% of the elements of the final knowledge base are derived from the ISI subject model.

